Whose Hands Were on It
The difficulty of building used to do two things at once. It revealed who made the work, and it forged the person who made it. We just made it optional.

Friends,
I just got back from a week away, the first real stretch of time off I have taken in longer than I can remember, a week to mark fifteen years married. Before I left I wrote and staged three articles in advance, the way you do when you are about to go quiet for a while, so nothing would pile up behind me.
Producing them was the part I could get ahead of. The other part does not load ahead and does not run on its own. A decision. A judgment call. A read that has to be right and has to be mine. And in the last tired push before vacation, ready to be done and gone, I came closer than I want to admit to skipping it on one of them.
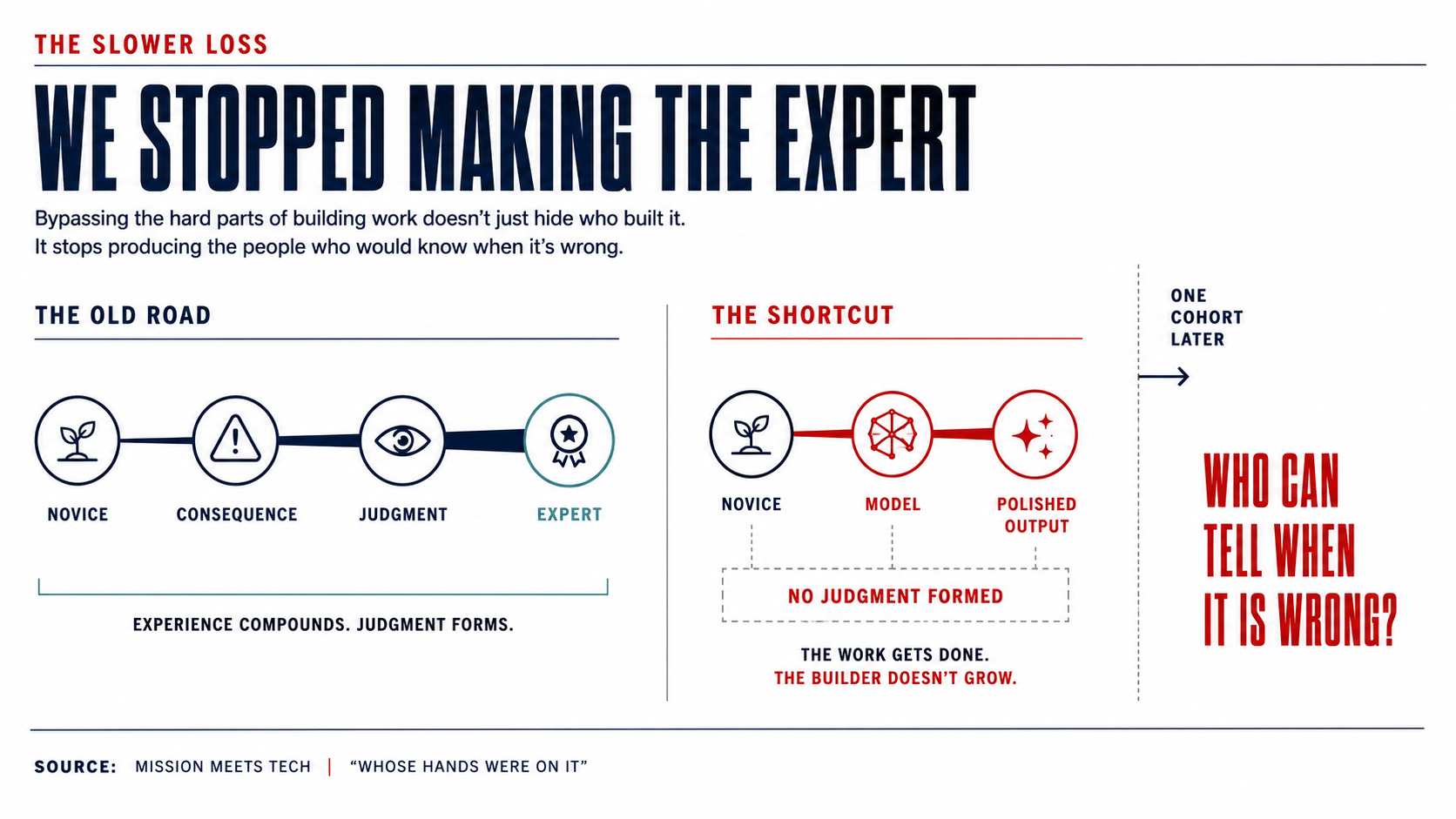
You used to be able to find a junior engineer by the seams. The work ran, but you could see where the pieces met, the small places where someone still learning had forced two things to fit and left a mark. A senior's work had no seams that showed. The only road from the first to the second ran through years of doing it, because the seams were where the learning happened. You closed them one at a time, by getting things wrong and paying for the mistake until you stopped.
Over the last two years the seams have been disappearing from a great deal of knowledge work, all at once.
A junior with a good model now ships work with no visible joints, and so does the senior, and in the shops that lean hardest on the tools the two are hard to tell apart. The output converged even though nothing that produced it did. The tool writes plausible work for anyone who asks, and removed the one signal we have spent our careers learning to read. Good work and bad work come out of it looking nearly identical at a glance.
The build was the receipt
For as long as people have made things, the work itself was proof of the person who made it. You could not produce deep, well-structured work without the depth that produced it. The difficulty did the filtering: it kept the people who had not done the work from producing things that looked as though they had.
There is an old law in software that says the same thing. In 1968 Melvin Conway argued that any system a group designs comes out shaped like the way that group communicates, so a team that talks in four silos ships a product with four seams. The industry has called it Conway's Law for half a century because it keeps proving true. Run it down to the single person and it sharpens: what one builder makes is a cast of how that builder thinks. The gaps in their understanding become the gaps in the thing they build, and the corners they cut become the corners the system cuts later, in the field, on the day it matters.
Michael Polanyi named the part that cannot be faked. We know more than we can tell. The knowledge that decides whether a thing is any good lives partly in the hands and partly in the judgment, where the expert could not write it down in full. It is the clinician who catches the interaction the chart missed, and the capture lead who reads a solicitation and knows by the second page that the bidder never opened the statement of work. That knowledge cannot be loaded into a prompt, and it cannot be recognized as missing by anyone who does not already carry it.
So the difficulty was doing two jobs at once. It filtered out the people who had not done the work, and it built the people who had, and those were never two separate events. The struggle and the credential were the same thing happening once.

The model is the constant. The person is everything else.
Hand the same model to a thousand people and you have handed all of them the same underlying capability, intern and thirty-year veteran alike. Everything that still differs in the work is coming from the person, because the person is the only part still in motion. The person is no longer most of the variable. The person is the variable.
The research is older and steadier than the noise. A 2023 study in the Proceedings of the National Academy of Sciences tracked more than ten thousand founders and found personality predicting outcomes at every stage, from first money to exit. A companion analysis of more than twenty-one thousand founder-led companies found the founder's personality often explained more of the success than the industry itself. Not the market, and not the timing. The person. The tools did not weaken that finding. They made it the whole contest.
Why the two look the same
A language model is fluent by design, so when you ask it for a market read or a clinical summary, it hands back something coherent and confident whether or not the person at the keyboard understood a word of the problem. Three philosophers put the mechanism precisely in a 2024 paper titled, without flinching, "ChatGPT is bullshit." The model is not lying, because lying requires caring about the truth enough to bend it on purpose. The model is indifferent to it. It produces the shape of a correct answer because that shape is what it was trained to produce, with no mechanism for knowing whether the answer is correct. That is why the surface comes together while the substance splits apart, in equal measure, for the deep builder and the shallow one.
The numbers are blunt. GitClear studied two hundred eleven million changed lines of code and found refactored code fell from about a quarter of all changes in 2021 to under a tenth by 2024, while copy-pasted code more than doubled and some measures of duplicated blocks rose roughly eightfold. Veracode ran better than a hundred models against eighty coding tasks and found about forty-five percent of the code came back carrying a security flaw, with the newer, larger models no more secure than the old ones. A separate scan of AI-assisted web applications found basic security controls missing across the board, standard headers absent and routine attacks left open. The systems looked finished. The protection was not there underneath.

Whether you can see any of that depends on who you are. Gary Klein spent a career studying how experts decide and found they recognize rather than weigh, a recognition paid for in years of living with the parts that broke. The expert sees the missing control the way you see a word spelled wrong on a page. The novice sees nothing, because on the surface there is nothing to see. John Sweller's work on cognitive load adds the last turn: the cleaner the document, the more of the reviewer's attention its surface consumes, leaving less to reach the substance below. The better the fake reads, the harder it is to see through.
We kept the credential and threw out the difficulty
The seam was never a flaw in the work. It was a receipt.
The difficulty was the apprenticeship itself, and the product was the proof the apprenticeship had been served. You could not produce expert work without doing the things that slowly turn a person into an expert, so holding the work told you the person had been through all of it. A model breaks that cleanly. It produces the output without the struggle, and the output stops being proof of anything about the person who handed it to you. I have spent half of this article on that consequence, and it is still the smaller half of the problem.
The larger half is what happens to the person. An expert can lean on the tool and stay an expert, because the judgment that lets them check it was built long before the tool arrived. A novice who leans on the same tool does not become an expert more slowly. They do not become one at all, because the tool runs the exact reps that would have built the judgment. The error that used to teach a hard lesson now gets resolved by asking for random changes until the bug goes quiet, and the seam closes without anyone learning how. The expert pulls further ahead, and the novice stops moving and cannot feel it, because the work looks for all the world like progress.
The road I am describing here is my own. I took a degree in journalism and then taught it at the advanced level, and you cannot teach a craft you have not made your own, so the teaching finished what the degree began: how to verify a claim before it leaves your hands, and how to write something a stranger has a reason to trust. Then I ran a software company for twelve years, and a company that size makes you every seat at once, the one who sells the work and the one who builds it and the one who answers for it when it breaks, which is Conway's law lived inside a single person. You learn what every part of the thing costs because you paid for all of it yourself. And then I was trained in capture and growth at the top of the federal health IT world, where you learn what actually wins and why, what an evaluator is really reading for, and where a system meets its boundary and quietly fails one. None of those four were quick. Not one could be skipped. Together they are the reps that built whatever it is you are reading right now.
Then it runs forward in time, and this is the part I would set in front of every program office in defense health. The seniors who can still tell a real system from a convincing one were forged in the years before the tool existed, in the difficulty that no longer stands in anyone's way. Behind them sits a cohort that was never made to struggle, because the struggle is optional now and the output looks the same on either side of it. The seniors age out and retire on schedule. So we lose twice. We go blind to who built the thing in front of us, and we shut down the line that produces the people who could have told us.
A failure that runs in a cycle comes back around at the exact moment the last people who remember the previous one have left the building.
Where the paper stops being paper
Bring this into the world I work in. A compliance volume is the easiest part of a federal proposal for a model to write: the requirements are published, the format is fixed, and the language is sitting in the training data waiting to be assembled. The one section an evaluator reads as proof of rigor is the section a model fakes most cleanly, while the controls it claims to describe live underneath it, where the model never went and the evaluator cannot see from the page.
Two proposals clear the same gate with the same clean row of green down the compliance matrix. One author has stood inside an assessment and defended a boundary in person. The other has never seen one. The two score the same, and they deploy the same, into the data environment that carries 9.5 million beneficiaries' records. They come apart at the first moment the system is under real load, in a clinic, on the day the audit trail the proposal described so cleanly turns out never to have been built.
We can move a strike across three time zones in milliseconds. We cannot read, off the paperwork in front of us, whether the firm we just trusted with a clinical system employs a single person who could actually build it.
What survives
If the build no longer carries the builder, reading it harder will not save anyone. The signal came off the artifact and onto the person, and that is where you now have to look. So stop treating polished output as proof of capability and start treating it as a claim to be tested against the human behind it. Ask for the artifact, not the assertion. By artifact I mean the thing itself rather than the words about it: the actual access control list, an audit log entry tied to a real user and a real action, a configuration that runs, a live endpoint behind an authorization boundary, the authorization number for every tool in the pipeline including the AI ones. A model will write the description of every one of those without breaking stride, and cannot produce the things themselves. The person who built them can put them in your hand inside an afternoon. The honest contractor is helped by the question. The one who generated a description of work they never did is the one it exposes.
Put the domain expert in the loop and on the hook, carrying the weight rather than bolted on at the end. And keep some of the difficulty in place on purpose, even when the tool makes it skippable, because those reps are the only known way to produce the next person who can check the tool's work. An organization that automates away its own apprenticeships is trading speed today against its ability to judge anything a few years from now, and it will not feel the trade until the bill arrives.
None of this fixes the politics of an award. The incumbent advantage outlives a sharper question, and so does the relationship. What the question fixes is the one thing still inside your hands: whether the work, once deployed, was done by someone who could do it, or by someone who could only describe it convincingly.
I almost skipped it myself
I will tell you something I am not proud of, because it is the truest thing in this article. Three pieces sat written and staged, ready to run while I was gone. It was the last night before a trip I had not taken in years, and I was tired and already half on vacation. I nearly scheduled the last one and walked out the door without the final read. This was the version of me that built every guardrail this operation runs on, the review passes and the checks and the standard I just got done telling you I hold. That version was ready to hand off the one part of the job that cannot be handed off, because it was easy and the work looked finished and no one would ever have known.
That is the entire argument, happening to the person who should be hardest to catch. The guardrails did not save me. They were all in place, every one I built, and a tired mind can walk straight past the whole stack, because process is the part the tool produces best and the part fatigue waves through fastest. The checks are necessary and they are not sufficient, because something still has to decide to run the last one. What saved the piece was stopping, against the pull, and actually doing the judgment, the one move I have spent this whole article telling you cannot be automated and cannot be skipped. I came within a click of skipping it myself.
Critical thinking is a decision you make every single time, not a system you install once and leave running, and the afternoon you are surest you can skip it is the exact afternoon it matters most. The moment I hand that decision to the machine, I am not better than the slop I have been warning you about. I am worse, because I knew exactly what I was setting down, and I let the machine's confidence stand in for my own.
The unsuspecting audience
The veteran never sees the model. She sees the instructions she carries home from the appointment, and whether the warning that should be on them is there or quietly missing. The program office never sees the builder. It sees a system that holds up in the clinic or fails there, in front of a patient. The buyer never sees the person at all, only a deliverable that looks, on its clean surface, very much like one from someone who knew what they were doing.
For my whole career the work was the window. You looked at what a person made and through it you saw the person, and that was how trust got built and reputations got earned and the serious got told apart from the loud. The tool did not make the work better or worse on average. What it did was quieter. It was slower to show its cost. It took the person out of the window and left the glass.
And the harder loss is the slower one. Ten years out, the question is not whether a model can build the clinical system, because it will. The question is whether anyone is left who can tell when it has built the wrong one. The build has already stopped showing us the builder. We are one cohort away from it having also stopped making them.
Find out whose hands were on it, while there are still hands worth finding.
Let's roll.
— Mary
Mission Meets Tech
The views expressed in this newsletter are my own and do not represent the official position of any organization. This content is for informational purposes only.
MMT Premium
This issue makes the case. Premium subscribers get the companion Capture Corner: how to read the builder when you can no longer read the build, the artifact-not-assertion checklist for source selection, the questions that separate a real domain expert in the loop from a name on an org chart, and a practical standard for protecting apprenticeship inside a team that has gone all in on AI tooling.
Founding Member rate: $199/year, locked permanently for the first 100 subscribers. Standard rate: $249/year or $29/month.
Premium adds 48-hour early access to deep-dive analysis, monthly Capture Intelligence Sheets with sourced action windows, direct Q&A access (reply to any premium issue), and tool discounts: ProposalPulse $14.99 per assessment, MarketPulse $35 per brief.
Subscribe at missionmeetstech.com/pricing.
Sources
[1] Melvin E. Conway, "How Do Committees Invent?" Datamation, April 1968 (a system's design mirrors the communication structure of the group that builds it). https://www.melconway.com/Home/Committees_Paper.html
[2] Michael Polanyi, The Tacit Dimension (1966; University of Chicago Press reissue, 2009). "We can know more than we can tell." https://press.uchicago.edu/ucp/books/book/chicago/T/bo6035368.html
[3] Andrej Karpathy, vibe coding post, X, February 2, 2025 (accept AI changes without reading them; when a bug resists, ask for random changes until it goes away; framed for throwaway projects). https://x.com/karpathy/status/1886192184808149383
[4] M. Freiberg and S.C. Matz, "Founder personality and entrepreneurial outcomes," PNAS (2023) (10,541 founder-startup dyads; personality tracks outcomes across the venture life cycle). https://www.pnas.org/doi/10.1073/pnas.2215829120
[5] McCarthy et al., "A personality-based analysis of 21,000 founder-led companies," Scientific Reports (2023) (founder personality often explained more variance in success than firmographics or industry category). https://www.nature.com/articles/s41598-023-41980-y
[6] M.T. Hicks, J. Humphries, and J. Slater, "ChatGPT is bullshit," Ethics and Information Technology, 26(2) (2024) (LLMs are indifferent to truth; they optimize for plausibility). DOI: 10.1007/s10676-024-09775-5. https://doi.org/10.1007/s10676-024-09775-5
[7] GitClear, "AI Copilot Code Quality 2025" (211 million changed lines; refactored/moved code fell from ~25% of changes in 2021 to under 10% by 2024; copy-pasted code more than doubled; duplicated blocks up ~8x). https://www.gitclear.com/ai_assistant_code_quality_2025_research
[8] Veracode, "2025 GenAI Code Security Report" (100+ models, 80 tasks; ~45% of generated code samples contained a security vulnerability; newer and larger models no more secure than older ones). https://www.veracode.com/blog/genai-code-security-report/
[9] Cloud Security Alliance, "Vibe Coding AI Governance Gap" research note (widespread absence of standard security controls in AI-assisted applications, including missing security headers and exposure to routine web attacks). https://labs.cloudsecurityalliance.org/wp-content/uploads/2026/06/CSA_research_note_vibe_coding_ai_governance_gap_20260602-csa-styled.pdf
[10] Gary Klein, Sources of Power: How People Make Decisions (MIT Press, 1998) (recognition-primed decision: experts recognize patterns built from accumulated consequence). https://catalogue.nla.gov.au/catalog/244831
[11] John Sweller, "Cognitive load during problem solving: Effects on learning," Cognitive Science, 12(2) (1988) (surface processing consumes the working memory needed to evaluate deeper structure). https://andymatuschak.org/files/papers/Sweller%20-%201988%20-%20Cognitive%20load%20during%20problem%20solving.pdf
[12] Kiteworks, "AI Compliance for Federal Contractors" (FedRAMP verification and tamper-evident logging for every AI tool that can reach CUI). https://www.kiteworks.com/regulatory-compliance/ai-compliance-federal-contractors/
