The Expert You Cannot Buy Off the Shelf
I was handed an AI-built pricing sheet last week with rates wrong enough to break a contract, and a hundred AI-written questions meant for someone else. Same root cause. The model is now the cheap part. The expert whose judgment makes it safe is the part you cannot buy, and the part the market is busy trying to replace.

Friends,
Someone handed me a pricing document last week. It set the labor rates for a federal bid, and the market norms inside it were wrong by a margin wide enough to sink the work. Had the company bid those numbers, it would have won a contract it could not staff and walked itself into failure.
I knew the rates were wrong the way you know a forged signature. One line priced a master's-degree professional with ten years in the field at 47 percent below the GSA rate. No one with that resume takes that rate. I have spent years walking labor rates against GSA schedules and the real market, and these did not match what it costs to put qualified people in seats. They had come out of an AI tool asked to establish what the market pays. It answered with confidence, and no one had checked the answer against anything real.
The same week, a different stack of AI work landed on me. Nearly a hundred questions, AI generated, sent to me to answer as a subcontractor. They had been written for a technology vendor and for the government. Not one of them fit the scope of my agreement. Someone had a machine generate a pile of questions and forwarded it without reading who it was for.
Two failures, one cause. A capable tool produced output, and the check that should have caught the error never ran. Sometimes no expert is in the room. Sometimes the expert is there and moving too fast to look. The model performs either way. The judgment that catches it is what goes missing.
That missing check is the whole story of AI in federal work right now, and it is not a technology problem. The model is close to a commodity. What makes it safe to use is the judgment of someone who has done the work the agent is now doing, and that judgment has to be built into the agent by hand. The market is selling agents as if that person is the cost they remove. That person is the product.
The expert is the product
The word "agent" hides who does the hardest part. Someone has to decide what the agent should know, what good looks like, and when to stop. That work belongs to a domain expert, and the engineer building the system cannot do it for them.
Most organizations never get that far. They buy a seat on Claude or ChatGPT for their people, roll it out, and believe they have adopted AI. They have bought a chat window. A chat window, a project, and an agent are three different things, and most of the building cannot tell them apart.
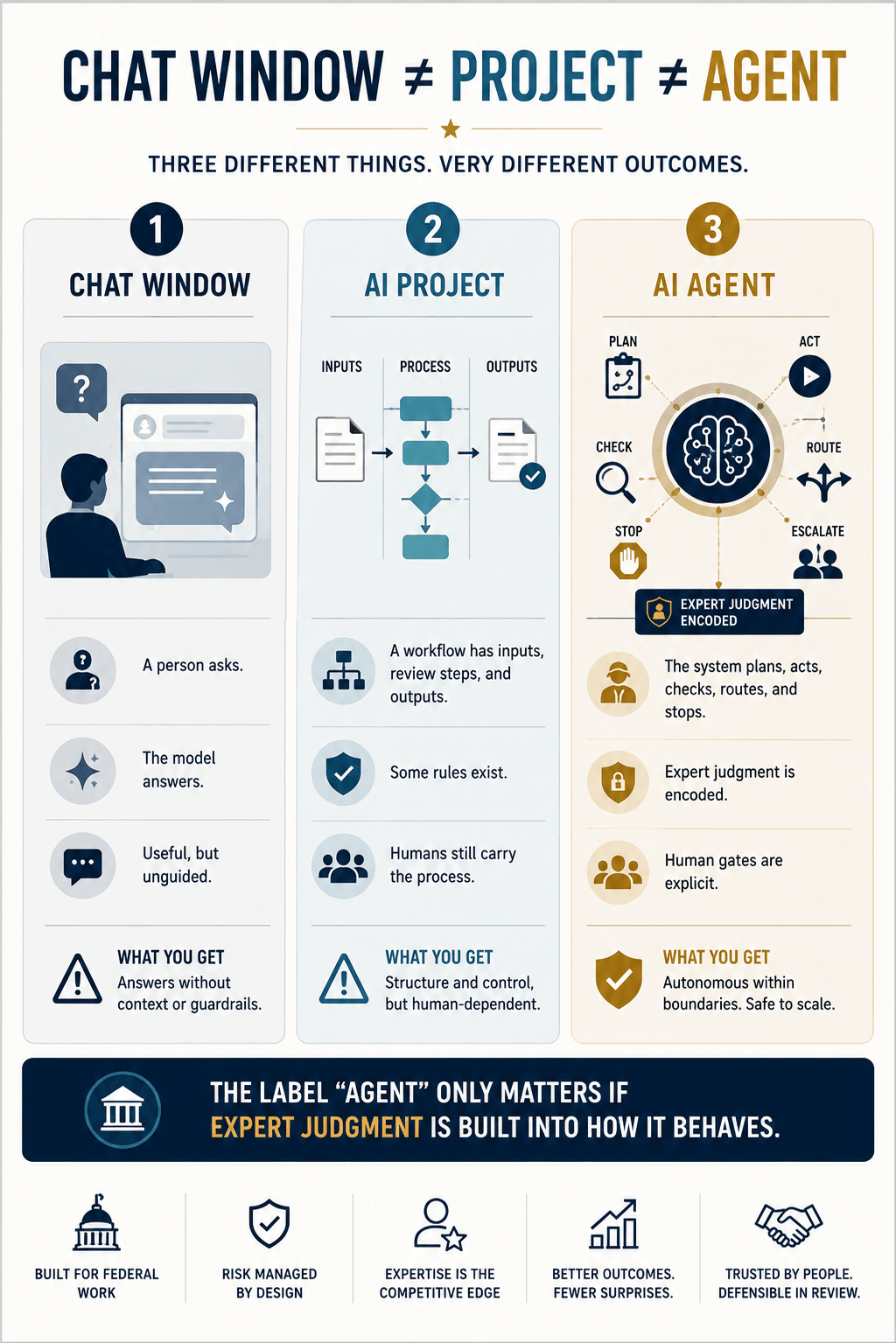
The danger lives in that confusion. A bare model answers every question with the same confidence whether it has the data or not. Ask it for a market rate and it produces one, grounded in nothing, with no rule telling it which source to trust or when to stop. It fills the silence with a confident number. The pricing sheet I was handed is what that looks like printed out.
There is no settled definition of an AI agent. Ask three vendors and you get three answers, from a single prompted model to a system that plans and acts on its own. The distance between those is enormous, and the same label covers both. What decides where a given agent lands is not the model. It is how much real expertise got wired into it.
Andrew Ng put numbers on that. On a standard coding benchmark, GPT-3.5 prompted once scored 48 percent. GPT-4 prompted once scored 67. The same GPT-3.5, wrapped in a loop that let it draft, test, and revise, scored 95. The weaker model, built well, beat the stronger model used raw. The architecture beat the upgrade.
Now carry that into capture. An engineer can build the loop, the retrieval, the place a human signs off. The engineer cannot tell the agent that a labor mix is unstaffable on sight, or which past-performance framing survives an evaluation, or that a question phrased a certain way tells the contracting officer the bidder never read the SOW. That knowledge lives in a capture and proposal SME who has lost bids and won them. The engineer wires the agent. The expert is what the agent knows.
I have put AI-guided proposal delivery into production at both ends of the scale, on a billion-dollar federal program and inside a small business, and the failure rhymes at both. On the large program, the scaffolding was already there: the review gates, the pricing discipline, the people who had run the play a hundred times. The agent inherited their judgment because their judgment was already in the building. The small business had none of that. The same tool, dropped into a shop without the expert layer, did not get smarter. It got faster at being wrong. Scale changes the blast radius. It does not change the cause.
And it is training, not a one-time build. The SME teaches the agent, corrects it, and teaches it again when the model shifts underneath. The human-in-the-loop discipline the proposal field already preaches for using AI applies just as hard to building it. The difference is that now the human is also the source of what the agent knows.
What the experts would have caught
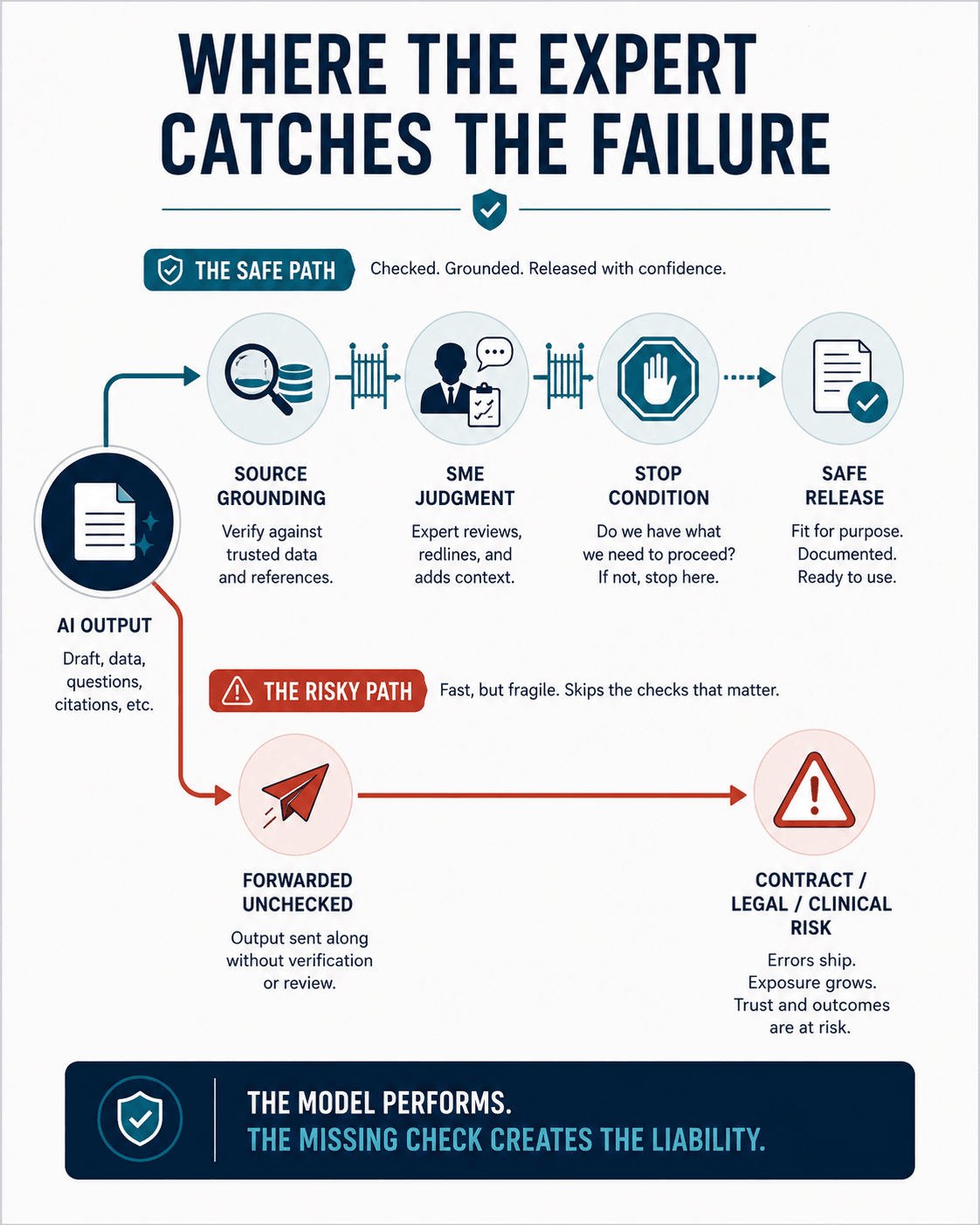
Walk back to the pricing sheet. The tool treated reference data as market truth, and federal pricing data does not work that way. GSA's own CALC rates, the ones an AI is most likely to scrape, are not-to-exceed ceilings. GSA says plainly they are one input in building a negotiation objective, not the answer. Its own inspector general found the CALC data incomplete, inaccurate, and duplicative. An AI that pulls those rates and reports them as the going market rate has misused them at the source. A capture SME knows that in their sleep. The tool did not, and neither did the person who sent the sheet.
Cost realism is a graded standard. FAR 15.404-1 lets the government test whether a proposed price is realistic for the work and downgrade a bid that is not. A GovCon risk list names the exact failure mode: fabricated labor categories feeding distorted pricing. The company was one submission away from pricing itself into a contract it could not deliver, and the evaluator would not have had to catch it. The math would have caught it for them.
The hundred questions are the same failure wearing a different coat. A machine produced volume, and a person forwarded it without checking who it was for or whether it applied. That is the homogenization every contracting shop is now seeing. The Air Force District of Washington's director of contracting, Colonel Villarreal, said it out loud: too many proposals now sound like they were written by the same robot. Volume up, signal down, and the human filter that used to separate them quietly removed.
The courts have started charging for it. A construction firm filed a brief at the Armed Services Board with citations more than seventy percent inaccurate. The board struck it. A protester at GAO submitted decisions that did not exist, and GAO dismissed the protest as a sanction, in what appears to be a first. A second GAO protest drew a warning that the citations bore the hallmarks of AI invention. One tracker counts thirty-one AI-misuse filings in federal procurement disputes last year, twenty-three at GAO. Fabricated citations. Struck briefs. Dismissed protests. Firms sanctioned for letting a machine write what an expert was supposed to read.
The practitioners who use AI well already know where the line sits. The field's own guidance is to treat every AI output like a first draft from a talented junior analyst, and to keep the experts on the win themes, the solutioning, and the price. Both failures I saw crossed that line in the same place. The expert was supposed to be there, and was not.
What the expert builds in
Training an agent is not fine-tuning a model. It is a capture professional sitting down and encoding what they know into the system the engineer built. The gap between an agent that holds and one that fails is what gets encoded, and only the expert can supply it.
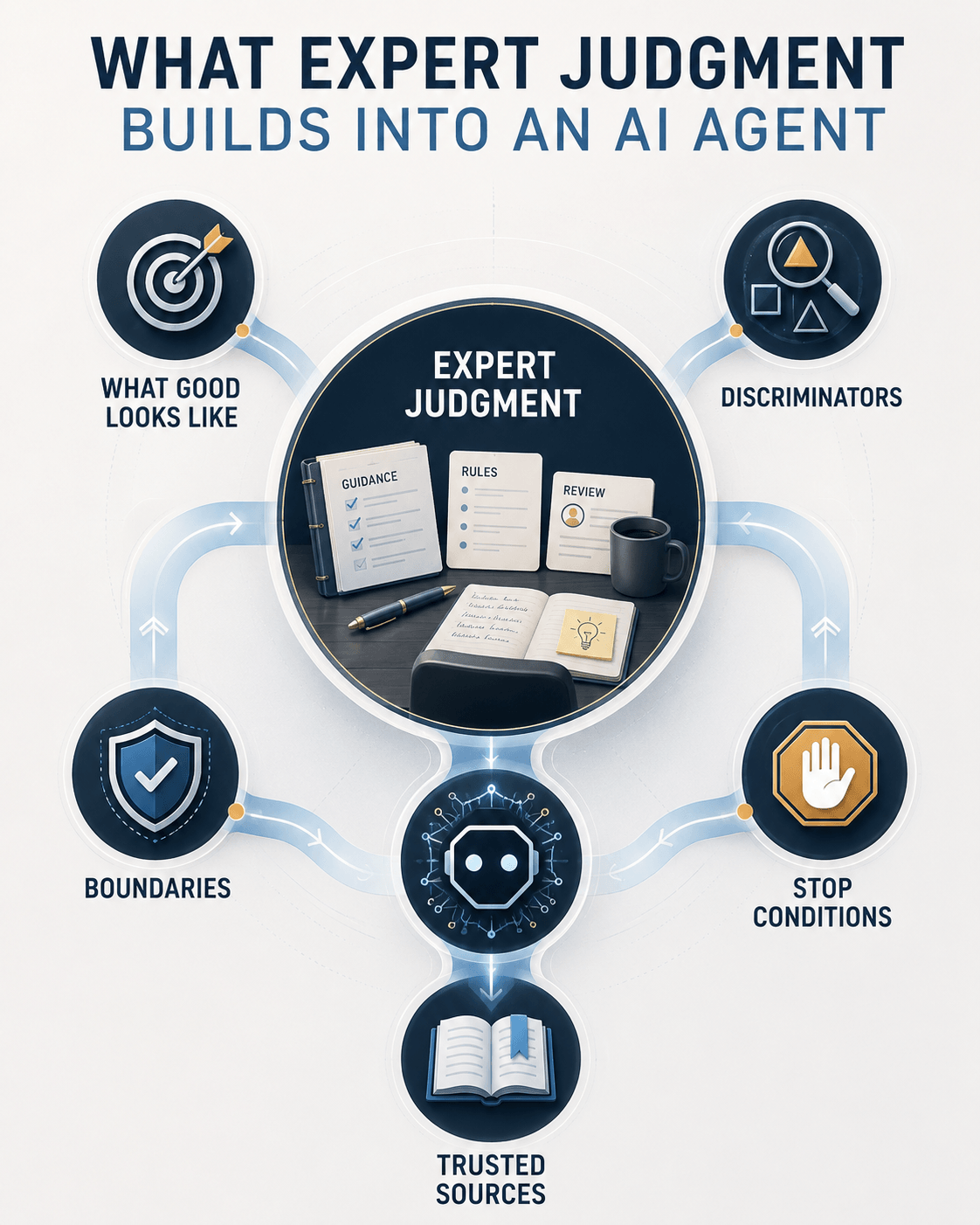
Start with what good looks like. A model can generate a pricing table. It cannot know that a master's-degree engineer with ten years does not work for 47 percent under GSA, because it has no feel for what the work costs to put in seats. The SME supplies that as a hard rule. These categories map to this scope. These rates close the staffing math. Anything outside the band stops and asks. The agent inherits a floor it could never see on its own.
Then the discriminators. A compliance matrix is the easy part, and AI builds it well. Knowing which requirements are table stakes and which ones move the evaluation score is the hard part, and it is the part that wins. The SME teaches the agent which threads to pull, the way they learned it, by losing bids that were fully compliant and lost anyway.
Then the boundaries. The hundred questions failed because no one had taught the system whose lane it was in. A capture SME carries scope in their bones: what belongs to the sub, what belongs to the prime, what belongs to the government, and what never leaves the building. Encode that and the agent routes the question to the right place or holds it. Skip it and the agent fires a hundred rounds at the wrong target.
Last, the stop conditions. The most valuable thing an expert knows is when to say no. When not to bid. When to escalate. When the honest answer is that the work cannot be staffed at that price. That judgment has to be written into the agent as a place where it halts and hands control back to a person. A stop condition is the line between an autonomous agent and an unsupervised one.
The grounding matters as much as the rules. An agent's judgment is only as good as what it reasons over. One working from the current schedule, the actual solicitation, and real labor data behaves nothing like one improvising over a general model and a thin slice of context. The expert knows which sources are authoritative and which are noise, and points the agent at the first kind. A commercial model bought off the shelf does not arrive knowing the difference.
And it is never finished. The SME corrects the agent, feeds it the example it got wrong, and does it again when the model underneath changes its behavior overnight. The discipline the proposal field already preaches for using AI, a human in the loop at every stage, is the discipline for building it. The engineer wires the room. The expert is the one standing in it who knows what right looks like, and the only one who can tell when the agent has drifted from it.
Who is selling it
The mismatch is structural. The companies selling federal agents staff with engineers, because building the system is an engineering problem. Making it safe is a capture problem, or a clinical one, and the people who can solve it are the ones the agent is pitched to replace. Buy the capability without the expert, and you have bought the half that acts and skipped the half that knows.
The smaller the shop, the louder the pitch and the thinner the safety net. The promise sold to a three-person business is that AI lets it bid like a thirty-person business, eighteen proposals a quarter instead of six. The capability is real. What the three-person shop does not have is the second capture veteran to catch the agent when it invents a rate or misreads a scope. A large program survives a bad draft because ten people touch it before it ships. A small business bets the company on a draft that went out the door without a senior set of eyes. AI widens that gap. It hands the widest version to the firms least able to absorb the loss.
When the handoff loses its human
Everything above still had a person in the loop, however briefly. The next turn removes them. Agents have started talking to each other, and the standards that let them do it are already in production. Anthropic released a protocol in late 2024 to let an AI reach outside systems. Google released another in 2025 to let agents call each other directly, and it now sits under the Linux Foundation with more than 150 organizations behind it, wired into the major clouds.
The danger has a name. Simon Willison calls it the lethal trifecta: an agent with access to private data, exposure to untrusted input, and the ability to send information back out. Hit all three and a malicious input can turn the agent against its own user. A clinical agent reading a chart, ingesting an outside message, and writing to a record hits all three. So does a proposal agent reading internal pricing, pulling a public solicitation, and submitting to a portal.
The measurements are bad. NIST red-teamed agent hijacking and watched the attack success rate climb from 11 percent to 81 percent against the strongest method. A Cloud Security Alliance survey found 82 percent of organizations had discovered AI agents running in their environment that they did not know were there. The agents are already loose, and most of the enterprises running them cannot see them or stop them. Frontier models also hit a wall on the exact work these systems are trusted to do alone. They finish almost any task that takes a human a few minutes and fail most that take more than a few hours. Short and supervised, they hold. Long and autonomous, they break.
Andrej Karpathy, who helped build this field, calls it the decade of agents rather than the year. The autonomy on every vendor slide is years from reliable. The systems are being trusted with it now anyway.
The rulebook has no clause for any of it. No FAR provision is written for the security of an autonomous agent, and Part 39 covers IT in terms that predate the technology. NIST stood up an AI Agent Standards Initiative in early 2026 and ran a public request for information on agent security because the floor does not exist yet. The capability is being acquired today. The standard that makes it safe to acquire is still being written. The one thing holding that gap is the expert in the loop, which is the exact thing agent-to-agent automation is built to remove.
This is already inside defense health
DHA launched its Data and Innovation Strategy in March and named Dr. Jesus Caban to run it. The Department of War published an AI strategy in January. VA has had an ambient AI scribe in clinical use since October and is moving toward autonomous agents on veteran health data. GAO reviewed thirteen AI acquisitions across DOD, DHS, GSA, and VA and found the governance trailing the buying. The FAR overhaul rewriting federal procurement under M-25-26 has no answer yet for the agent question.
In capture, the expert is a proposal lead. In defense health, the expert is a clinician, a pharmacist, a readiness officer. The person who knows this drug interacts with that one, that the protocol shifts for a deployed population, that this is the contraindication you never miss. The rule does not change with the domain. An agent drafting a care instruction is only as safe as the clinical judgment built into it and the clinician checking it on the way out. The model does not carry that knowledge. A person who has practiced does, and the agent has to be taught by one.
Every one of those programs is making the choice the pricing sheet made in miniature. Buy the capability, and decide later, separately, whether the expert who makes it safe is in the room. In defense health that room is a clinic, and the cost of getting it wrong is not a lost bid.
The expert is the build
I learned this building that kind of architecture on a federal program, before the policy caught up to it. The model was the afternoon's work. The authorization was the months, written for a system that never changes, wrapped around one that changed every week. That gap was the whole job, and no model upgrade has ever shipped with the thing that closes it.
Authoring the judgment is only half. The organization on the other end has to change how it works to keep that judgment real: people trained to supervise an agent instead of trust it, override rates someone actually reads, a gate that is real and not a rubber stamp. Roughly four in five enterprise AI efforts fail, and they fail on people and process long before they fail on models.
The speed the tool sells is the thing that erodes the gate. The faster the agent lets you move, the more tempting it is to sign without reading. The check has to hold on the busy afternoon, because that is the one where the error slips through.
Before you buy the agent, ask whose judgment is inside it, and require the answer in writing. Write the capture lead and the clinician into the requirement. Put the expert in the room when the agent is built, in the loop when it runs, and on the hook when it is wrong. The program that does that gets an agent. The program that buys the model and calls it done gets a liability with good grammar.
We can stand up an agent that reads a veteran's chart and drafts her chemotherapy instructions in seconds. We have not made it reliable enough to know when it is wrong. The distance between what it can do and what we can trust it to do alone is filled by one thing. A human who has done the work, whose judgment is built into the agent on the way in and who checks it on the way out.
The veteran does not see the model. She sees the instructions she carries home, and whether the contraindication is in them or missing. The company does not feel the model. It feels the contract it cannot staff. The subcontractor does not read the model. She reads a hundred questions written for someone else.
In every case the model performed. In every case the expert was the part that was supposed to be there and was not.
The market will keep telling you the agent is what you are buying. Building the agent is the easy part. Building the expert into it is the work. Skip it, and the thing you turn on is a confident machine that cannot tell when it is wrong.
Let's roll.
— Mary
Mission Meets Tech
The views expressed in this newsletter are my own and do not represent the official position of any organization. This content is for informational purposes only.
MMT Premium
This issue makes the case. Premium subscribers get the companion Capture Corner: how to vet whether a real SME's judgment is actually inside the agent you are buying, how to pressure-test an AI-built pricing sheet against CALC and cost realism before it ships, the human-gate standard for AI-generated questions and content, and the agent-security questions to put to any vendor selling you an "agent."
Founding Member rate: $199/year, locked permanently for the first 100 subscribers. Standard rate: $249/year or $29/month.
Premium adds 48-hour early access to deep-dive analysis, monthly Capture Intelligence Sheets with sourced action windows, direct Q&A access (reply to any premium issue), and tool discounts: ProposalPulse $14.99 per assessment, MarketPulse $35 per brief.
Subscribe at missionmeetstech.com/pricing.
Sources
[1] Andrew Ng, "How Agents Can Improve LLM Performance," DeepLearning.AI, The Batch. Source for the HumanEval figures (GPT-3.5 48.1%, GPT-4 67.0%, GPT-3.5 in an agent loop 95.1%). https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance/
[2] Andreessen Horowitz, "What Is an AI Agent?" a16z podcast (no settled definition); Anthropic, "Building Effective Agents" (workflow versus agent distinction). https://a16z.com/podcast/what-is-an-ai-agent/ ; https://www.anthropic.com/research/building-effective-agents
[3] U.S. General Services Administration, OASIS+ Buyers Guide / Complete Market Research (CALC+ rates as not-to-exceed ceiling rates). https://www.gsa.gov/buy-through-us/products-and-services/professional-services/buy-services/oasis-plus/buyers-guide/complete-market-research
[4] GSA Office of Inspector General, Report A180068, December 23, 2019 (CALC data incomplete, inaccurate, and duplicative). https://www.gsaig.gov/sites/default/files/audit-reports/A180068_1.pdf
[5] Federal Acquisition Regulation 15.404-1, "Proposal analysis techniques" (cost realism). https://www.acquisition.gov/far/15.404-1
[6] Coley GSA, "AI in Government Contracting: Risks and Benefits" (fabricated labor categories). https://www.coleygsa.com/ai-in-government-contracting-risks-benefits/
[7] Markon, "Why AI Alone Won't Win Government Contracts," August 27, 2025 (Col. Villarreal, AFDW; keep SMEs on win themes, solutioning, and price). https://www.markonsolutions.com/blog/why-ai-alone-wont-win-government-contracts-and-what-to-do-instead
[8] Armed Services Board of Contract Appeals, Huffman Construction, ASBCA Nos. 62591, 62783, October 23, 2025 (over 70% of citations inaccurate; brief struck). https://www.asbca.mil/LinkClick.aspx?fileticket=eAIy2KSL_Zg%3D&portalid=143
[9] Government Accountability Office, Oready, LLC, B-423649, September 25, 2025 (sanctions dismissal), via GovCon Judicata. https://www.govconjudicata.com/single-post/alert-using-sanctions-gao-dismisses-protest-where-protester-used-non-existent-citations-and-cases
[10] Government Accountability Office, Bramstedt Surgical, B-424064, January 28, 2026 ("hallmarks" of AI-generated authority), via PilieroMazza. https://www.pilieromazza.com/beware-the-hallmarks-of-ai-recent-gao-decision-provides-cautionary-tale-for-protesters/
[11] Burr & Forman, "Gen-AI Misuse in Procurement Litigation" (31 filings in 2025; 23 at GAO). https://www.burr.com/government-contracting/gen-ai-misuse-in-procurement-litigation
[12] GovBidLab, "AI Government Proposal Writing Compliance Guide," March 26, 2026 (treat output like a junior analyst's first draft). https://govbidlab.com/blog/ai-government-proposal-writing-compliance-guide
[13] Anthropic, "Introducing the Model Context Protocol," November 19, 2024. https://www.anthropic.com/news/model-context-protocol
[14] Google Developers Blog, "A2A: A New Era of Agent Interoperability," April 9, 2025; Linux Foundation, "A2A Protocol Surpasses 150 Organizations," 2026. https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/ ; https://www.linuxfoundation.org/press/a2a-protocol-surpasses-150-organizations-lands-in-major-cloud-platforms-and-sees-enterprise-production-use-in-first-year
[15] Simon Willison, "The Lethal Trifecta for AI Agents," June 16, 2025. https://simonw.substack.com/p/the-lethal-trifecta-for-ai-agents
[16] NIST, "Strengthening AI Agent Hijacking Evaluations," January 2025 (attack success 11% to 81%). https://www.nist.gov/news-events/news/2025/01/technical-blog-strengthening-ai-agent-hijacking-evaluations
[17] Cloud Security Alliance / Token Security, "82% of Enterprises Have Unknown AI Agents in Their Environments," April 21, 2026. https://cloudsecurityalliance.org/press-releases/2026/04/21/new-cloud-security-alliance-survey-reveals-82-of-enterprises-have-unknown-ai-agents-in-their-environments
[18] METR, "Measuring AI Ability to Complete Long Tasks," March 19, 2025 (reliable under a few minutes, failing past a few hours). https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
[19] NIST, "Announcing the AI Agent Standards Initiative," February 17, 2026; Federal Register, "Request for Information Regarding Security Considerations for AI Agents," January 8, 2026. https://www.nist.gov/news-events/news/2026/02/announcing-ai-agent-standards-initiative-interoperable-and-secure ; https://www.federalregister.gov/documents/2026/01/08/2026-00206/request-for-information-regarding-security-considerations-for-artificial-intelligence-agents
[20] Cloud Security Alliance research note, "NIST AI Agent Standards: Federal Framework" (no FAR clause for AI-agent security); FAR Part 39, "Acquisition of Information Technology." https://labs.cloudsecurityalliance.org/research/csa-research-note-nist-ai-agent-standards-federal-framework/ ; https://www.acquisition.gov/far/part-39
[21] Defense Health Agency, "Data and Innovation Strategy Launched to Improve Warfighter Readiness," March 11, 2026 (Dr. Jesus Caban). https://dha.mil/News/2026/03/11/17/05/Data-and-Innovation-Strategy-launched-to-improve-warfighter-readiness
[22] Department of War, "Artificial Intelligence Strategy for the Department of War," memo dated January 9, 2026. https://media.defense.gov/2026/Jan/12/2003855671/-1/-1/0/artificial-intelligence-strategy-for-the-department-of-war.pdf
[23] VA News, "Powered by AI: Improving Veteran Care Experience," November 20, 2025 (ambient AI scribe launched October 2025). https://news.va.gov/143486/powered-by-ai-improving-veteran-care-experience/
[24] Government Accountability Office, GAO-26-107859 (in-depth review of 13 AI acquisitions at DOD, DHS, GSA, and VA). https://www.gao.gov/products/gao-26-107859
[25] Office of Management and Budget, M-25-26, "Overhauling the Federal Acquisition Regulation." https://www.whitehouse.gov/wp-content/uploads/2025/02/M-25-26-Overhauling-the-Federal-Acquisition-Regulation-002.pdf
[26] RAND Corporation, James Ryseff, Brandon De Bruhl, and Sydne Newberry, "The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed," August 13, 2024 (more than 80 percent of AI projects fail, twice the rate of non-AI IT projects; failures attributed to people, process, and data, not the model). https://www.rand.org/pubs/research_reports/RRA2680-1.html
[27] Andrej Karpathy, interview on the Dwarkesh Podcast, 2025 ("the decade of agents," on why autonomous agents are not yet reliable enough to deploy). https://www.dwarkesh.com/p/andrej-karpathy
[28] GovDash, "GovCon AI: How AI Can Scale Your Proposal Team," January 13, 2026 (vendor claim that AI lets a three-person team handle 18 to 24 bids per quarter instead of six). https://www.govdash.com/blog/govcon-ai-how-ai-can-scale-your-proposal-team
